Spring Data JDBC – Defining custom queries and projections
Take your skills to the next level!
The Persistence Hub is the place to be for every Java developer. It gives you access to all my premium video courses, monthly Java Persistence News, monthly coding problems, and regular expert sessions.
Some of the most important features in every persistence framework are the ones that enable us to query data and retrieve it in our preferred format. In the best case, you can easily define and execute standard queries, but you can also define very complex ones. Spring Data JDBC provides you with all of this, and I will show you how to use these features in this article.
As the name indicates, Spring Data JDBC is one of the modules of Spring Data and follows the same concepts that you might already know from other Spring Data modules. You define a set of entities that get mapped to database tables and group them into aggregates. For each aggregate, you can define a repository. The best way to do that is to extend one of Spring Data JDBC’s standard repository interfaces. These provide you with standard operations to read and write entities and aggregates. For this article, I expect you to be familiar with repositories in Spring Data. If you’re not, please take a look at the section about repositories in my introduction to Spring Data JPA. They work in the same way as the repositories in Spring Data JDBC.
By default, Spring Data JDBC’s repositories can only fetch all entities of a specific type or one entity by its primary key. If you need a different query, you need to define it yourself. You can use Spring Data’s popular derived query feature for simple queries. And if it gets more complex, you can annotate the repository method with a @Query annotation and provide your own statement. Before we take a closer look at both options and discuss non-entity projections, let’s take a quick look at the domain model used in this article.
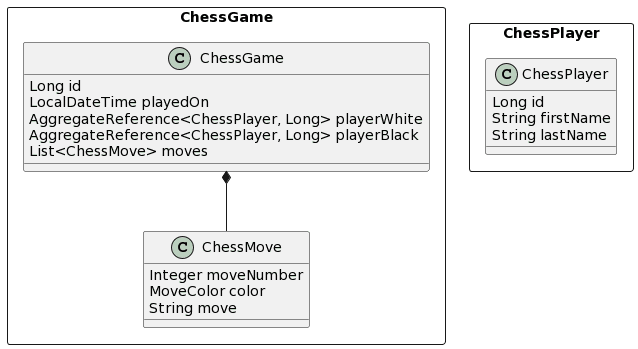
Example domain model
The domain model that we will use in the examples of this post consists of 2 aggregates. The ChessPlayer aggregate only consists of the ChessPlayer entity. The ChessGame aggregate is independent of the ChessPlayer and consists of the entity classes ChessGame and ChessMove with a one-to-many association between them. The ChessGame entity class also maps 2 foreign key references to the ChessPlayer aggregate. One of them references the player with the white and the other to the player playing the black pieces.
Derived queries in Spring Data JDBC
Similar to other Spring Data modules, Spring Data JDBC can generate a query statement based on the name of a repository method. This is called a derived query. A derived query is a great way to generate a simple query statement that doesn’t require JOIN clauses and doesn’t use more than 3 query parameters.
Here you can see a few typical examples of such queries.
public interface ChessGameRepository extends CrudRepository<ChessGame, Long> {
List<ChessGame> findByPlayedOn(LocalDateTime playedOn);
List<ChessGame> findByPlayedOnIsBefore(LocalDateTime playedOn);
int countByPlayedOn(LocalDateTime playedOn);
List<ChessGame> findByPlayerBlack(AggregateReference<ChessPlayer, Long> playerBlack);
List<ChessGame> findByPlayerBlack(ChessPlayer playerBlack);
}
Derived queries in Spring Data JDBC follow the same principles as in other Spring Data modules. If your method name matches one of the following patterns, Spring Data JDBC tries to generate a query statement:
- find<some string>By<where clause>
- get<some string>By<where clause>
- query<some string>By<where clause>
- exists<some string>By<where clause>
- count<some string>By<where clause>
Spring Data JDBC parses the <where clause> and maps it to attributes of the entity class managed by the repository interface. Joins to other entity classes are not supported.
By default, Spring Data JDBC generates an equal comparison for each referenced attribute and compares it with a method parameter with the same name. You can customize the comparison by using keywords like “After”, “Greater Than”, “Like”, and “IsTrue”. You can find a full list of all supported keywords in the official documentation. You can also combine multiple parameters in your WHERE clause declaration using the keywords “And” and “Or”.
Based on this information, Spring Data JDBC generates an SQL statement and executes it when you call the repository method in your business code.
List<ChessGame> games = gameRepo.findByPlayedOnIsBefore(LocalDateTime.of(2022, 05, 19, 18, 00, 00));
games.forEach(g -> log.info(g.toString()));
2022-05-20 18:39:56.561 DEBUG 2024 --- [ main] o.s.jdbc.core.JdbcTemplate : Executing prepared SQL query
2022-05-20 18:39:56.562 DEBUG 2024 --- [ main] o.s.jdbc.core.JdbcTemplate : Executing prepared SQL statement [SELECT "chess_game"."id" AS "id", "chess_game"."played_on" AS "played_on", "chess_game"."player_black" AS "player_black", "chess_game"."player_white" AS "player_white" FROM "chess_game" WHERE "chess_game"."played_on" < ?]
Please remember that this feature is designed for simple queries. As a rule of thumb, I recommend only using it for queries that don’t require more than 2-3 query parameters.
Custom queries in Spring Data JDBC
If your query is too complex for a derived query, you can annotate your repository method with a @Query annotation and provide a database-specific SQL statement. If you’re familiar with Spring Data JPA, this is basically the same as the native query feature, but it doesn’t require you to set the nativeQuery flag because Spring Data JDBC doesn’t provide its own query language.
As you can see in the following code snippet, defining your own query is as simple as it sounds, and you can use all features supported by your database.
public interface ChessGameRepository extends CrudRepository<ChessGame, Long> {
@Query("""
SELECT g.*
FROM chess_game g
JOIN chess_move m ON g.id = m.chess_game
WHERE m.move = :move
""")
List<ChessGame> findByMovesMove(String move);
}
In this case, I use a statement that selects all columns of the chess_game table of each game in which the provided move was played. The moves are stored in the chess_move table, which gets mapped to the ChessMove entity class. In the SQL statement, I use a simple JOIN clause to join the 2 tables and provide a WHERE clause to filter the result.
The WHERE clause uses the named bind parameter :move, and the repository method defines a method parameter with the same name. When executing this statement, Spring Data JDBC automatically sets the value of the method parameter move as the bind parameter with name move.
As you can see, the query itself doesn’t provide any information about the format in which I want to retrieve the selected information. This is defined by the return type of the repository method. In this case, the SQL statement selects all columns of the chess_game table, and Spring Data JDBC will map the result to ChessGame entity objects.
List<ChessGame> games = gameRepo.findByMove("e4");
games.forEach(g -> log.info(g.toString()));
As you can see in the log output, Spring Data JDBC used the provided SQL statement, set all method parameters as bind parameter values, and executed the query. And when it mapped the query result to ChessGame objects, it had to execute an additional query to get all moves played in the game and initialize the List<ChessMove> moves association. This is called an n+1 select issue, which can cause performance problems. The best way to reduce the performance impact is to keep your aggregates small and concise or use non-entity projections, which I will show in the next section.
2022-05-20 19:06:16.903 DEBUG 16976 --- [ main] o.s.jdbc.core.JdbcTemplate : Executing prepared SQL query
2022-05-20 19:06:16.905 DEBUG 16976 --- [ main] o.s.jdbc.core.JdbcTemplate : Executing prepared SQL statement [SELECT g.*
FROM chess_game g
JOIN chess_move m ON g.id = m.chess_game
WHERE m.move = ?
]
2022-05-20 19:06:17.018 DEBUG 16976 --- [ main] o.s.jdbc.core.JdbcTemplate : Executing prepared SQL query
2022-05-20 19:06:17.018 DEBUG 16976 --- [ main] o.s.jdbc.core.JdbcTemplate : Executing prepared SQL statement [SELECT "chess_move"."move" AS "move", "chess_move"."color" AS "color", "chess_move"."move_number" AS "move_number", "chess_move"."chess_game_key" AS "chess_game_key" FROM "chess_move" WHERE "chess_move"."chess_game" = ? ORDER BY "chess_game_key"]
2022-05-20 19:06:17.037 INFO 16976 --- [ main] com.thorben.janssen.TestQueryMethod : ChessGame [id=16, playerBlack=IdOnlyAggregateReference{id=10}, playerWhite=IdOnlyAggregateReference{id=9}, moves=[ChessMove [moveNumber=1, color=WHITE, move=e4], ChessMove [moveNumber=1, color=BLACK, move=e5]]]
Non-entity/non-aggregate projections in Spring Data JDBC
Entity objects are not the only projection supported by Spring Data JDBC. You can also retrieve your query result as Object[] or map each record to a DTO object. Working with Object[]s is very uncomfortable and gets only rarely used. I recommend using the DTO projection for all use cases that don’t require the entire aggregate. That ensures that you don’t execute any unnecessary statements to initialize associations you’re not using and improves the performance of your application.
To use a DTO projection, you need to define a DTO class. That’s a simple Java class with an attribute for each database column you want to select. Unfortunately, Spring Data JDBC doesn’t support interface-based projections, which you might know from Spring Data JPA.
public class ChessGamePlayerNames {
private Long gameId;
private LocalDateTime playedOn;
private String playerWhiteFirstName;
private String playerWhiteLastName;
private String playerBlackFirstName;
private String playerBlackLastName;
// omitted getter and setter methods for readability
@Override
public String toString() {
return "ChessGamePlayerNames [gameId=" + gameId + ", playedOn=" + playedOn + ", playerBlackFirstName="
+ playerBlackFirstName + ", playerBlackLastName=" + playerBlackLastName + ", playerWhiteFirstName="
+ playerWhiteFirstName + ", playerWhiteLastName=" + playerWhiteLastName + "]";
}
}
As long as the aliases of the selected database columns match the attribute names of your DTO class, Spring Data JDBC can map each record of your query’s result set automatically. The only thing you need to do is to set the return type of your repository method to your DTO class or a List of your DTO classes.
public interface ChessGameRepository extends CrudRepository<ChessGame, Long> {
@Query("""
SELECT g.id as game_id,
g.played_on as played_on,
w.first_name as player_white_first_name,
w.last_name as player_white_last_name,
b.first_name as player_black_first_name,
b.last_name as player_black_last_name
FROM chess_game g
JOIN chess_player w ON g.player_white = w.id
JOIN chess_player b ON g.player_black = b.id
""")
List<ChessGamePlayerNames> findGamePlayerNamesBy();
}
As you can see, the query statement and the projection are independent of your aggregates and their boundaries. That’s another benefit of a non-entity projection. It gives you the freedom and flexibility to fetch the data in the form that best fits your business logic.
Spring Data JDBC executes the provided SQL statement when you use that repository method in your business code. And when it retrieves the result, it maps each record of the result set to a ChessGamePlayerNames object.
List<ChessGamePlayerNames> games = gameRepo.findGamePlayerNamesBy();
games.forEach(g -> log.info(g.toString()));
2022-05-20 19:09:16.592 DEBUG 12120 --- [ main] o.s.jdbc.core.JdbcTemplate : Executing prepared SQL query
2022-05-20 19:09:16.593 DEBUG 12120 --- [ main] o.s.jdbc.core.JdbcTemplate : Executing prepared SQL statement [SELECT g.id as game_id,
g.played_on as played_on,
w.first_name as player_white_first_name,
w.last_name as player_white_last_name,
b.first_name as player_black_first_name,
b.last_name as player_black_last_name
FROM chess_game g
JOIN chess_player w ON g.player_white = w.id
JOIN chess_player b ON g.player_black = b.id
]
2022-05-20 19:09:16.675 INFO 12120 --- [ main] com.thorben.janssen.TestQueryMethod : ChessGamePlayerNames [gameId=16, playedOn=2022-05-19T18:00, playerBlackFirstName=A better, playerBlackLastName=player, playerWhiteFirstName=Thorben, playerWhiteLastName=Janssen]
In the log output, you can see that Spring Data JDBC only executed the query defined for the repository method. In the previous example, it had to perform an additional query to initialize the mapped association from the ChessGame to the ChessMove entities. DTOs don’t support mapped associations and, due to that, don’t trigger any additional query statements.
Conclusion
Spring Data JDBC provides 2 options to define custom queries:
- Derived queries are a great fit for all simple queries that don’t require any JOIN clauses and don’t use more than 3 query parameters. They don’t require you to provide any custom SQL statements. You only need to define a method in your repository interface that follows Spring Data JDBC’s naming convention. Spring then generates the query statement for you.
- If your query gets more complex, you should annotate your repository method with a @Query annotation and provide a custom SQL statement. You must ensure that your SQL statement is valid and matches your database’s SQL dialect. When you call the repository method, Spring Data JDBC takes that statement, sets the provided bind parameter values, and executes it.
You can use different projections for both types of queries:
- The easiest one is the entity projection. Spring Data JDBC then applies the mapping defined for your entity class to each record in the result set. If your entity class contains mapped associations to other entity classes, Spring Data JDBC executes additional queries to initialize these associations.
Entity projections are a great fit if you want to change data or if your business logic requires the entire aggregate. - Object[]s are a rarely used projection that can be a good fit for read-only operations. They enable you to only select the columns you need.
- DTO projections provide the same benefits as Object[] projections but using them is much more comfortable. That’s why they are more commonly used and my preferred projection for read-only operations.
As you saw in the example, DTO projections are indepent of your aggregates and their boundaries. This enables you to query the data in the format that fits your business logic.
