How to implement complex full-text search with Hibernate Search
Take your skills to the next level!
The Persistence Hub is the place to be for every Java developer. It gives you access to all my premium video courses, monthly Java Persistence News, monthly coding problems, and regular expert sessions.
This is the second part of the Full-Text Search with Hibernate Search series. In the first part, I showed you how to add Hibernate Search to your project and to perform a very basic full-text query which returned all entities which contained a set of words. This query already returned a much better result than the typical SQL or JPQL query with a WHERE message LIKE :searchTerm clause. But Hibernate Search can do a lot more.
But you can do a lot more than that with Hibernate Search. It provides you an easy way to use Lucene’s analyzers to process the indexed Strings and also find texts that use different word forms or even synonyms of your search terms.
The 3 phases of an analyzer
Let’s have a quick look at the general structure of an analyzer before I show you how to create one with Hibernate Search. It consists of 3 phases, and each of them can perform multiple steps. The CharFilter adds, removes or replaces certain characters. That is often used to normalize special characters like ñ or ß. The Tokenizer splits the text into multiple words. The Filter adds, removes or replaces specific tokens.

The separation in 3 phases and multiple steps allows you to create very complex analyzers based on a set of small, reusable components. I will use it in this post to extend the example from the previous post so that I get the same results when I search for “validate Hibernate”, “Hibernate validation” and “HIBERNATE VALIDATION”.
That requires the search to handle words in upper and lower case in the same way and to recognize that “validate” and “validation” are two different forms of the same word. The first part is simple and you could achieve that in a simple SQL query. But the second one is something you can’t do easily in SQL. It is a common full-text search requirement which you can achieve with a technique called stemming. It reduces the words in the index and in the search query to its basic form.
OK, let’s define an analyzer that ignores the case upper and lower case and that uses stemming.
Define a custom Analyzer
As you can see in the following code snippet, you can do that with an @AnalyzerDef annotation, and it’s not too complicated.
@AnalyzerDef(
name = “textanalyzer”,
tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class),
filters = {
@TokenFilterDef(factory = LowerCaseFilterFactory.class),
@TokenFilterDef(factory = SnowballPorterFilterFactory.class,
params = { @Parameter(name = “language”, value = “English”) })
}
)
The analyzer definition is global and you can reference it by its name. So, better make sure to use an expressive name that you can easily remember. I choose the name textanalyzer in this example because I define a generic analyzer for text messages. It’s a good fit for most simple text attributes.
CharFilter
This example doesn’t require any character normalization or any other form of character filtering. The analyzer, therefore, doesn’t need any CharFilter.
Tokenizer
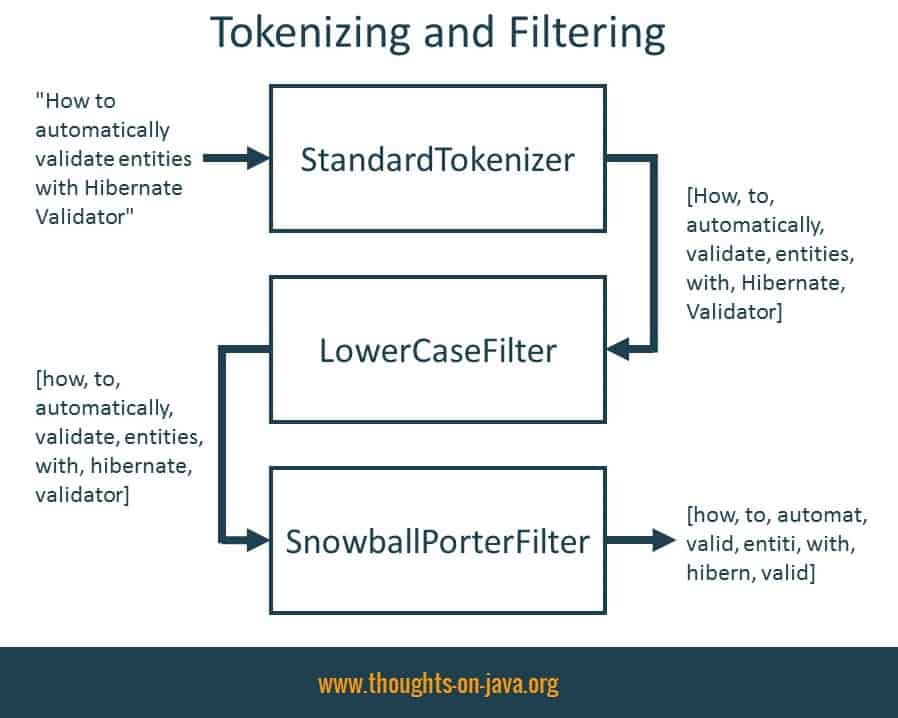
But it needs a Tokenizer. This one is required by all custom analyzers. It splits the text into words. In this example, I want to index my twitter messages. These are simple text messages which can be split at whitespaces and punctuations. A Tokenizer created by Lucene’s StandardTokenizerFactory can split these messages easily into words. It takes the String “How to automatically validate entities with Hibernate Validator” and splits it into a String[] {“How”, “to”, “automatically”, “validate”, “entities”, “with”, “Hibernate”, “Validator”}.
After that is done, you can apply Filter to the tokens to ignore case and add stemming.
Filter
In this example, I use the LowerCaseFilterFactory that transforms all tokens to lower case. It takes the String[] {“How”, “to”, “automatically”, “validate”, “entities”, “with”, “Hibernate”, “Validator”} and transforms it into {“how”, “to”, “automatically”, “validate”, “entities”, “with”, “hibernate”, “validator”}. That is basically the same as you would do in your JPQL query.
The SnowballPorterFilterFactory is more interesting. It creates a Filter that performs the stemming. As you can see in the code snippet, the @TokenFilterDef of the SnowballPorterFilterFactory requires an additional @Parameter annotation that provides the language that shall be used by the stemming algorithm. Almost all of my tweets are English so I set it to English. It takes the array of lower case String {“how”, “to”, “automatically”, “validate”, “entities”, “with”, “hibernate”, “validator”} and transforms each of them into its stem form {“how”, “to”, “automat”, “valid”, “entiti”, “with”, “hibern”, “valid”}.
That’s all you need to do to define the Analyzer. The following graphic summarizes the effect of the configured Tokenizer and Filter steps.
Use a custom Analyzer
You can now reference the @AnalyzerDef by its name in an @Analyzer annotation to use it for an entity or an entity attribute. In the following code snippet, I assign the analyzer to the message attribute of the Tweet entity.
@Indexed
@Entity
public class Tweet {
@Column
@Field(analyzer = @Analyzer(definition = “textanalyzer”))
private String message;
...
}
Hibernate Search applies the textanalyzer when it indexes the message attribute. It also applies it transparently when you use an entity attribute with a defined analyzer in a full-text query. That makes it easy to use and allows you to change an Analyzer without adapting your business code. But be careful, when you change an Analyzer for an existing database. I requires you to reindex your existing data.
FullTextEntityManager fullTextEm = Search.getFullTextEntityManager(em); QueryBuilder tweetQb = fullTextEm.getSearchFactory().buildQueryBuilder().forEntity(Tweet.class).get(); Query fullTextQuery = tweetQb.keyword().onField(Tweet_.message.getName()).matching(searchTerm).createQuery(); List<Tweet> results = fullTextEm.createFullTextQuery(fullTextQuery, Tweet.class).getResultList();
Summary
As you’ve seen in this post, Hibernate Search provides an easy to use integration of the Lucene analyzer framework. You can globally define an Analyzer with an @AnalyzerDef annotation. It can consist of up to 3 phases:
- The CharFilter adds, removes or replaces certain characters. This is often used to normalize special characters like ñ or ß.
- The Tokenizer splits the text into multiple words.
- The Filter adds, removes or replaces certain tokens. I used Filters in this example to change the tokens to lower case and apply stemming.
