Dual Writes – The Unknown Cause of Data Inconsistencies
Take your skills to the next level!
The Persistence Hub is the place to be for every Java developer. It gives you access to all my premium video courses, monthly Java Persistence News, monthly coding problems, and regular expert sessions.
Since a lot of new applications are built as a system of microservices, dual writes have become a widespread issue. They are one of the most common reasons for data inconsistencies. To make it even worse, I had to learn that a lot of developers don’t even know what a dual write is.

Dual writes seem to be an easy solution to a complex problem. If you’re not familiar with distributed systems, you might even wonder why people even worry about it.
That’s because everything seems to be totally fine … until it isn’t.
So, let’s talk about dual writes and make sure that you don’t use them in your applications. And if you want to dive deeper into this topic and learn various patterns that help you to avoid this kind of issue, please take a look at my upcoming Data and Communication Patterns for Microservices course.
What is a dual write?
A dual write describes the situation when you change data in 2 systems, e.g., a database and Apache Kafka, without an additional layer that ensures data consistency over both services. That’s typically the case if you use a local transaction with each of the external systems.
Here you can see a diagram of an example in which I want to change data in my database and send an event to Apache Kafka:
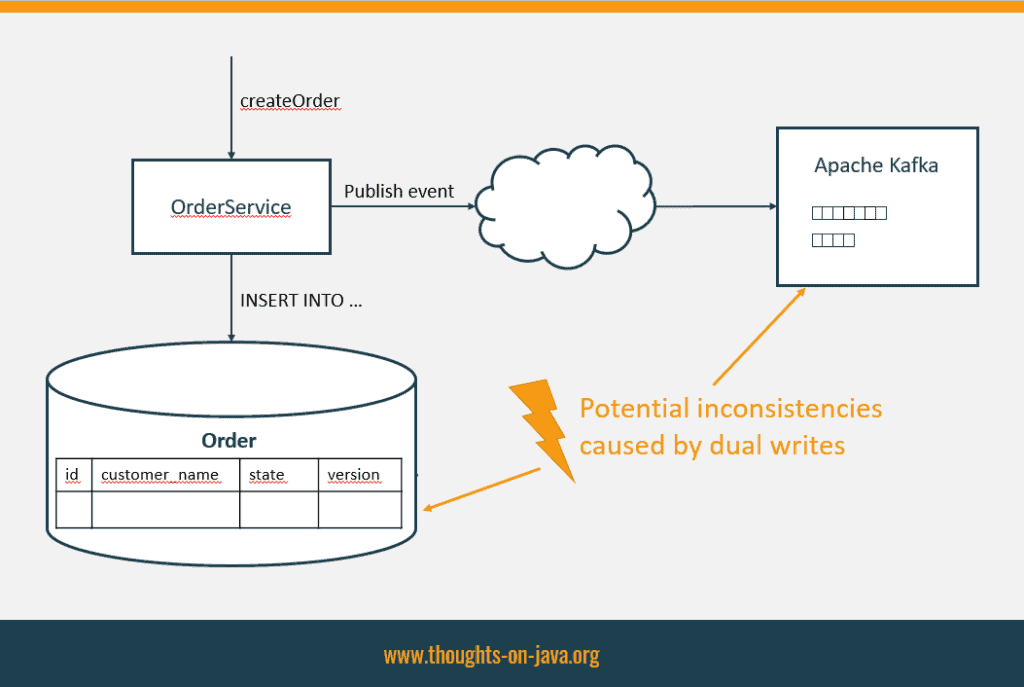
As long as both operations are successful, everything is OK. Even if the first transaction fails, it’s still fine. But if you successfully committed the 1st transaction and the 2nd one fails, you are having an issue. Your system is now in an inconsistent state, and there is no easy way to fix it.
Distributed transactions are no longer an option
In the past, when we build monoliths, we used distributed transactions to avoid this situation. Distributed transactions use the 2 phase commit protocol. It splits the commit process of the transaction into 2 steps and ensures the ACID principles for all systems.
But we don’t use distributed transactions if we’re building a system of microservices. These transactions require locks and don’t scale well. They also need all involved systems to be up and running at the same time.
So what shall you do instead?
3 “solutions” that don’t work
When I discuss this topic with attendees at a conference talk or during one of my workshops, I often hear one of the following 3 suggestions:
- Yes, we are aware of this issue, and we don’t have a solution for it. But it’s not that bad. So far, nothing has happened. Let’s keep it as it is.
- Let’s move the interaction with Apache Kafka to an after commit listener.
- Let’s write the event to the topic in Kafka before you commit the database transaction.
Well, it should be obvious that suggestion 1 is a rather risky one. It probably works most of the time. But sooner or later, you will create more and more inconsistencies between the data that’s stored by your services.
So, let’s focus on options 2 and 3.
Post the event in an after commit listener
Publishing the event in an after commit listener is a pretty popular approach. It ensures that the event only gets published if the database transaction was successful. But it’s difficult to handle the situation that Kafka is down or that any other reason prevents you from publishing the event.
You already committed the database transaction. So, you can’t easily revert these changes. Other transactions might have already used and modified that data while you tried to publish the event in Kafka.
You might try to persist the failure in your database and run regular cleanup jobs that seek to recover the failed events. This might look like a logical solution, but it has a few flaws:
- It only works if you can persist the failed event in your database. If the database transaction fails, or your application or the database crash before you can store the information about the failed event, you will lose it.
- It only works if the event itself didn’t cause the problem.
- If another operation creates an event for that business object before the cleanup job recovers the failed event, your events get out of order.
These might seem like hypothetical scenarios, but that’s what we’re preparing for. The main idea of local transactions, distributed transactions, and approaches that ensure eventual consistency is to be absolutely sure that you can’t create any (permanent) inconsistencies.
An after commit listener can’t ensure that. So, let’s take a look at the other option.
Post the event before committing the database transaction
This approach gets often suggested after we discussed why the after commit listener doesn’t work. If publishing the event after the commit creates a problem, you simply publish it before we commit the transaction, right?
Well, no … Let me explain …
Publishing the event before you commit the transaction enables you to roll back the transaction if you can’t publish the event. That’s right.
But what do you do if your database transaction fails?
Your operations might violate a unique constraint, or there might have been 2 concurrent updates on the same database record. All database constraints get checked during the commit, and you can’t be sure that none of them fails. Your database transactions are also isolated from each other so that you can’t prevent concurrent updates without using locks. But that creates new scalability issues. To make it short, your database transaction might fail and there is nothing you can, or want to do about it.
If that happens, your event is already published. Other microservices probably already observed it and triggered some business logic. You can’t take the event back.
Undo operations fail for the same reasons, as we discussed before. You might be able to build a solution that works most of the time. But you are not able to create something that’s absolutely failsafe.
How to avoid dual writes?
You can choose between a few approaches that help you to avoid dual writes. But you need to be aware that without using a distributed transaction, you can only build an eventually consistent system.
The general idea is to split the process into multiple steps. Each of these steps only operates with one data store, e.g., the database or Apache Kafka. That enables you to use a local transaction, asynchronous communication between the involved systems and an asynchronous, potentially endless retry mechanism.
If you only want to replicate data between your services or inform other services that an event has occurred, you can use the outbox pattern with a change data capture implementation like Debezium. I explained this approach in great detail in the following articles:
- Implementing the Outbox Pattern with Hibernate
- Implementing the Outbox Pattern with CDC using Debezium
And if you need to implement a consistent write operation that involves multiple services, you can use the SAGA pattern. I will explain it in more detail in one of the following articles.
Conclusion
Dual writes are often underestimated, and a lot of developers aren’t even aware of the potential data inconsistencies.
As explained in this article, writing to 2 or more systems without a distributed transaction or an algorithm that ensures eventual consistency can cause data inconsistencies. If you work with multiple local transactions, you can’t handle all error scenarios.
The only way to avoid that is to split the communication into multiple steps and only write to one external system during each step. The SAGA pattern and change data capture implementations, like Debezium, use this approach to ensure consistent write operation to multiple systems or to send events to Apache Kafka.
